ここ3ヶ月くらいPythonの勉強をしてまして、練習諸々兼ねて食べログの情報を自動で取得してExcelに吐くコードを書いてみました。
食べログスクレイピングのPythonコード
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 | #! python3 # t-log.py - 食べログのエリアページから店舗情報などを取得する import requests, bs4, time, openpyxl # 必要そうなものをインポート from datetime import datetime url = '★ここにINPUT用のURLを入れる★' # ★INPUTのURLを指定 res = requests.get(url) # 変数resにINPUTのURLを格納 res.raise_for_status() # エラーチェック now = datetime.now() file_time = now.strftime('%Y%m%d-%H%M%S') print(file_time) no_starch_soup = bs4.BeautifulSoup(res.text) # リクエストしたURLの内容を取得 # TODO ページャーのMAXを把握する elems = no_starch_soup.select('span[class="c-page-count__num"]') # ページャー関連の数値を取得 print(type(elems)) # 確認(いらなそう) print(len(elems)) # 要素の数を表示 print(type(elems[0])) # 要素のTypeを表示 max_shop = elems[2].getText() # INPUTにおけるMAX店舗数を取得 print('一覧ページの総店舗数は' + (max_shop) + 'です。') # MAX店舗数を表示 max_page = str(-(-(int(max_shop)) // 20)) # MAXページURL末尾の数字を計算 print('最大ページ数は' + (max_page) + 'です。') # MAXページ数を表示 max_page_url = (url) + (max_page) + '/' # MAXページURLを作成 print('最終ページのURLは ' + (max_page_url) + ' です。') # MAXページURLを表示 time.sleep(1) print('情報取得を開始します...') # 場繋ぎで表示 time.sleep(1) shop_name = [] # 空のリストを作成 shop_link = [] # 空のリストを作成 shop_star = [] # 空のリストを作成 #〇一覧ページ #・個別ページのURL一覧を取得 i = 1 # ループ用の変数を設定、URL構造的にこれがよさそうだった。 e = 0 # 通算実行回数カウント用の変数を設定(max店舗数で取得終了させる用) while True: print('ページをダウンロード中 {}...'.format(url)) # 取得対象ページを表示 res = requests.get(url) # 対象ページをリクエスト res.raise_for_status() # エラーチェック soup = bs4.BeautifulSoup(res.text) # 変数soupでページ内容を取得 elems = soup.select('a[class="list-rst__rst-name-target cpy-rst-name"]') # 変数elemsで店名・リンクを取得 shop_name.extend(elems) # 店舗名のリストを更新 shop_link.extend(elems) # 店舗リンクのリストを更新 shop_link_temp = [] # 空のリストを作成(ループ時はリセットが目的) shop_link_temp.extend(elems) # 店舗リンク(temp)のリストを更新 # TODO ループ内の店舗URLを取得 n = 0 # ループ内ループ用の変数を設定(20回で次の一覧ページに飛ぶ用) while True: print('-----一覧ページ(' + str(i) + '/' + (max_page) + ')内、' + str((n) + 1) + '回目の店舗情報取得を行います。-----') shop_kobetsu_url = shop_link_temp[n].get('href') res_kobetsu = requests.get(shop_kobetsu_url) soup_kobetsu = bs4.BeautifulSoup(res_kobetsu.text) res_kobetsu.raise_for_status() star_elems = soup_kobetsu.select('span[class="rdheader-rating__score-val-dtl"]') # 変数star_elemsで点数を取得 print('※一覧ページ内' + str(n + 1) + '回目・' + '通算' + str(e + 1) + '回目') shop_kobetsu_name = shop_link_temp[n].getText() print('店舗名は ' + (shop_kobetsu_name) + ' です。') print('店舗URLは ' + (shop_kobetsu_url) + ' です。') print('点数は ' + (star_elems[0].getText()) + 'です。') shop_star.extend(star_elems) # TODO: 次の店舗に進む if ((e + 1) % 20) == 0: # ページ内20回目で通算回数をプラスしてbrake e += 1 time.sleep(2) break elif (e + 1) == int(max_shop): # 通算回数が最大店舗数と同じになったらbrake break else: # その他の実行回数の場合カウントをそれぞれ追加 time.sleep(2) # 気持ちsleepさせて負荷を掛け過ぎないようにする n += 1 e += 1 # TODO 実行回数に応じて処理を分岐 if i == int(max_page): # URL末尾がmax_pageだった場合brake break # TODO: 「次の20件」に進む else: prev_link = soup.select('a[rel="next"]')[0] # aタグのrel="next"が「次の20件」なので指定。 url = prev_link.get('href') # 変数urlを「次の20件」のリンクに更新 print('-----次の一覧ページURLは ' + (url) + ' です。-----') # 場繋ぎで表示 time.sleep(0.5) # なんとなくスリープさせる。 i += 1 # ループ回数の値を更新 print('-----結果を表示します。-----') # 前置き print('-----【店舗名一覧は以下の通りです。】-----') for elem in shop_name: # 店名を表示 print(elem.getText()) time.sleep(0.05) print('-----【店舗リンク一覧は以下の通りです。】-----') for link_elem in shop_link: # 各店リンクを表示 print(link_elem.get('href')) time.sleep(0.05) print('-----【店舗点数一覧は以下の通りです。】-----') for star_elem in shop_star: # 各店の点数を表示 print(star_elem.getText()) time.sleep(0.05) wb = openpyxl.Workbook() sheet = wb.active sheet.title = '出力結果' # Excel見出しを入れる sheet['A1'].value = 'No.' sheet['B1'].value = '店舗名' sheet['C1'].value = '店舗URL' sheet['D1'].value = '点数' excel_num = len(shop_star) for a in range(excel_num): sheet.cell(row=a+2,column=1).value = a +1 for index,tenmei in enumerate(shop_name): sheet.cell(row=2+index,column=2).value = tenmei.getText() for index,tenpourl in enumerate(shop_link): sheet.cell(row=2+index,column=3).value = tenpourl.get('href') for index,tenpostar in enumerate(shop_star): if tenpostar.getText() == '-': # ハイフンの場合 sheet.cell(row=2+index,column=4).value = tenpostar.getText() else: sheet.cell(row=2+index,column=4).value = float(tenpostar.getText()) wb.save('Tabelog_' + str(file_time) + '.xlsx') print('リスト出力が完了しました。') |
コードの補足
5行目の★部分にINPUTのURL(取得したい画面のURL)を入れます。
入れる画面のイメージは以下のような形式のもので、「エリア(や業態)の一覧画面」といった形のものです。
https://tabelog.com/tokyo/A1331/rstLst/washoku/
必要な機能群については事前にインストールしておいてくださいませ。
スクールの先生からは「何としても動かす、という意志を感じるコードですね」と言われたので、要はまあ最適化の余地に溢れたコードなのだと思います。(数年後に「ようこんなん公開したな」と恥ずかしくなってそうですね、楽しみです)
スクレイピングのイメージ
以下の項目を取得してくる仕組みになっています。
・店舗名
・店舗URL
・点数
画面で言えば以下のような部分です。
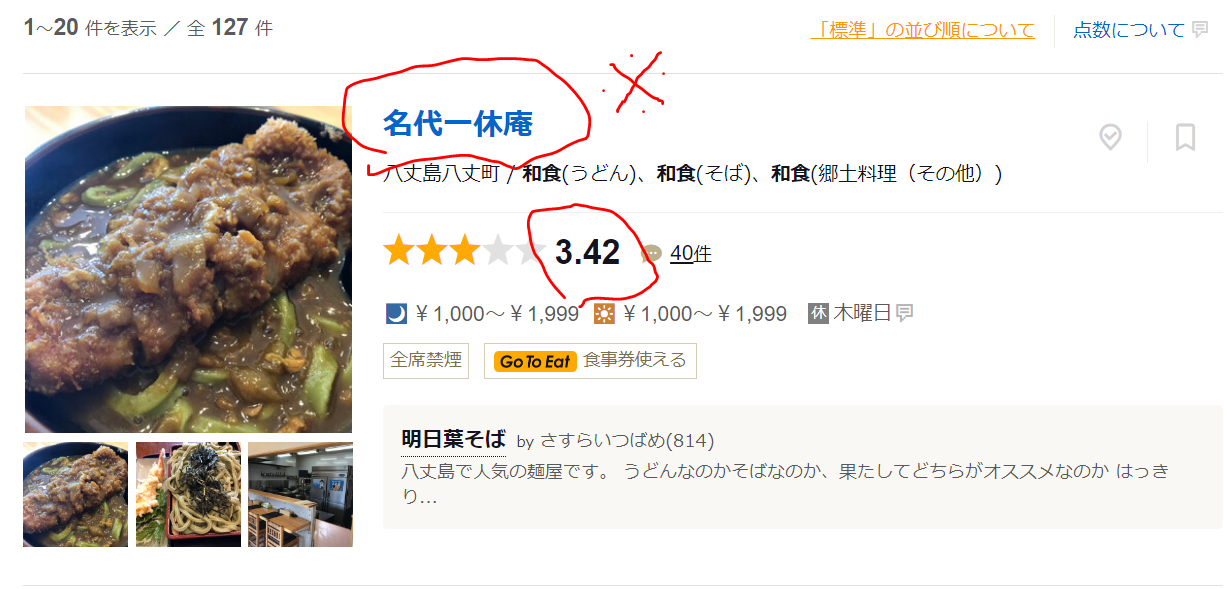
点数については、厳密には店舗ページに潜って取ってきてます。
なぜ一覧から取らないかというと、開店間もない店舗は点数が「-」だったりするのですが、その場合ソース上の要素として取得がしづらく、店舗ページに潜った方が取得が楽だったためです。
※また、おいおい店舗ページ内の「営業時間」とか「決済方法」みたいにいろんな情報を取得できるようにカスタマイズしたかったので、初期に各ページに潜ってしまうロジックを追加したかった、という意図もあります。
スクレイピングした情報の出力イメージ
以下のように、デフォルトのフォルダにExcelで吐き出されます。

ファイル吐き出しの際には9~10行目で実行時間を拾ってきていて、その時間をファイル名に使うため、連続実行しても別ファイルとして出力されます。
おわりに
エリア・業態の店舗や点数リストを作って分析ができそうなど、素人でも数ヶ月で実務レベルで使えそうなど、Pythonってすごいですね。
取得項目を増やすなど、改変してきたいと思います。
ちなみにオンラインプログラミングスクールの「Codecamp」で勉強してました。
上記のような「Beautiful Soup 4」によるWebスクレイピングや「Selenium」によるブラウザの自動操作(メールの自動送信など)が学べました。要領の良い方なら1~2ヶ月くらいでもっとプログラミングスキルを身に付けられると思います。
最後まで読んでいただきありがとうございました。